Parsa Kavehzadeh
AI Researcher at Huawei Canada

I am Parsa Kavehzadeh, an NLP researcher specializing in the development and optimization of Large Language Models (LLMs). Currently, I work at Huawei Technologies Canada, where I introduced Sorted LLaMA, a method for integrating nested submodels into a single LLM, and developed a confidence-based early exiting mechanism to accelerate inference.
I earned my MSc in Computer Science at York University under the supervision of Professor Enamul Hoque, focusing on natural language interactions with visualizations, including chart comprehension and reasoning. My research also encompassed a novel chart pretraining method and a survey on chart question answering. Previously, I completed my BSc in Computer Engineering at Amirkabir University of Technology, exploring deep learning for anomaly detection and text chunking.
My interests include efficient LLM training, inference acceleration, and multi-modal systems integrating NLP and computer vision. I’ve published in top-tier conferences like EACL, EMNLP, and EuroVis and received recognition such as MVP at Huawei Noah’s Ark Lab.
selected publications
-
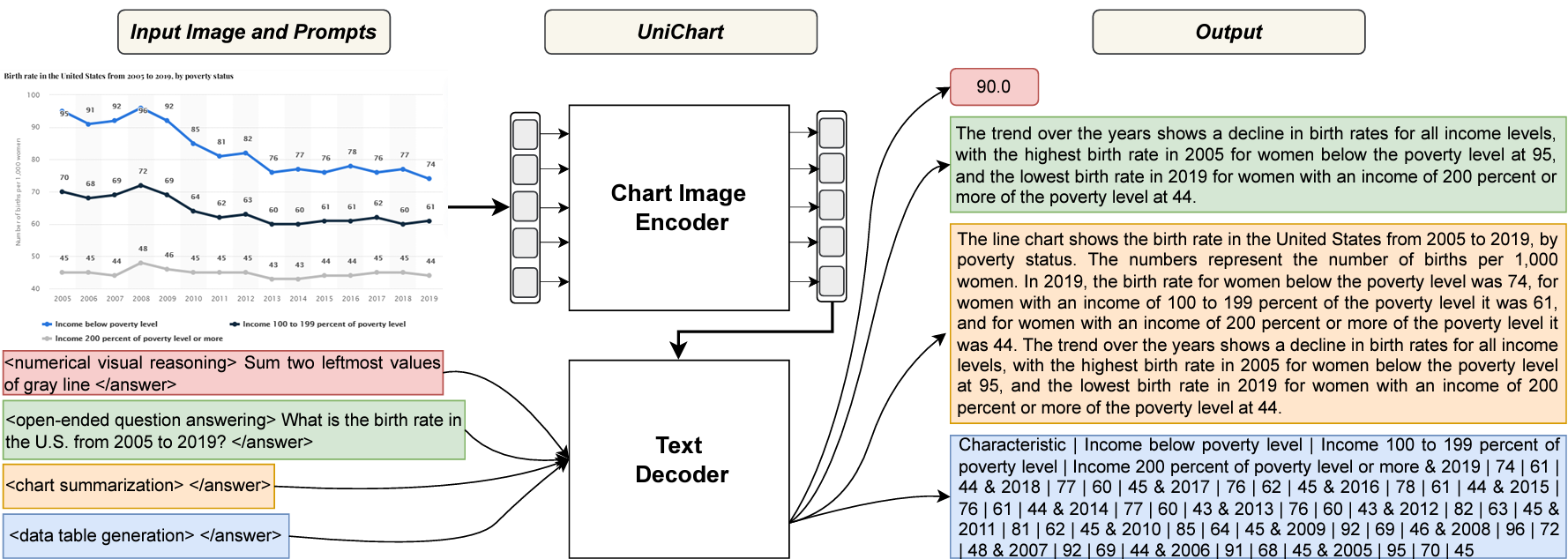 UniChart: A Universal Vision-language Pretrained Model for Chart Comprehension and ReasoningIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Dec 2023
UniChart: A Universal Vision-language Pretrained Model for Chart Comprehension and ReasoningIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Dec 2023 -
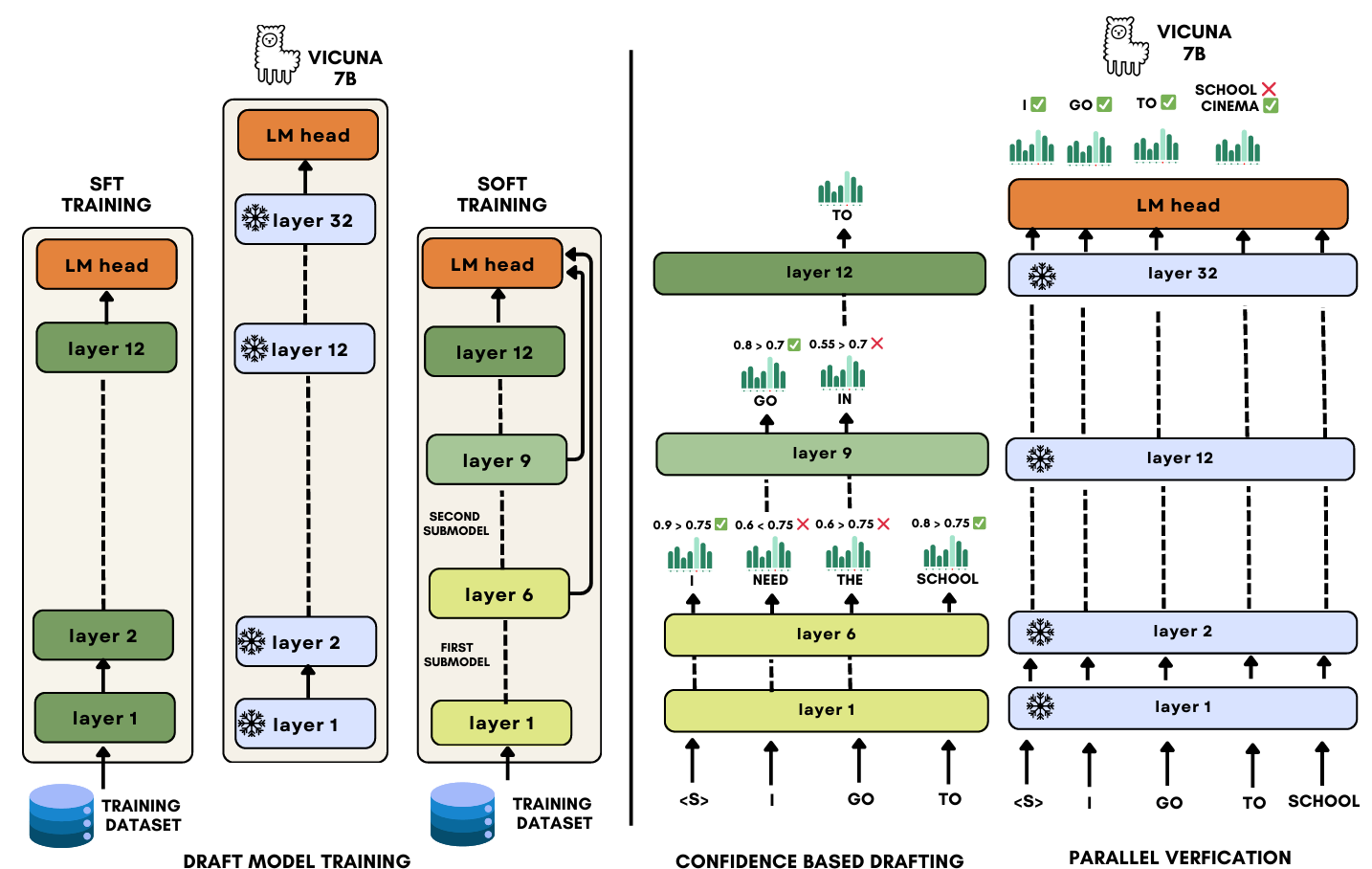 S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language ModelsDec 2024
S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language ModelsDec 2024 -
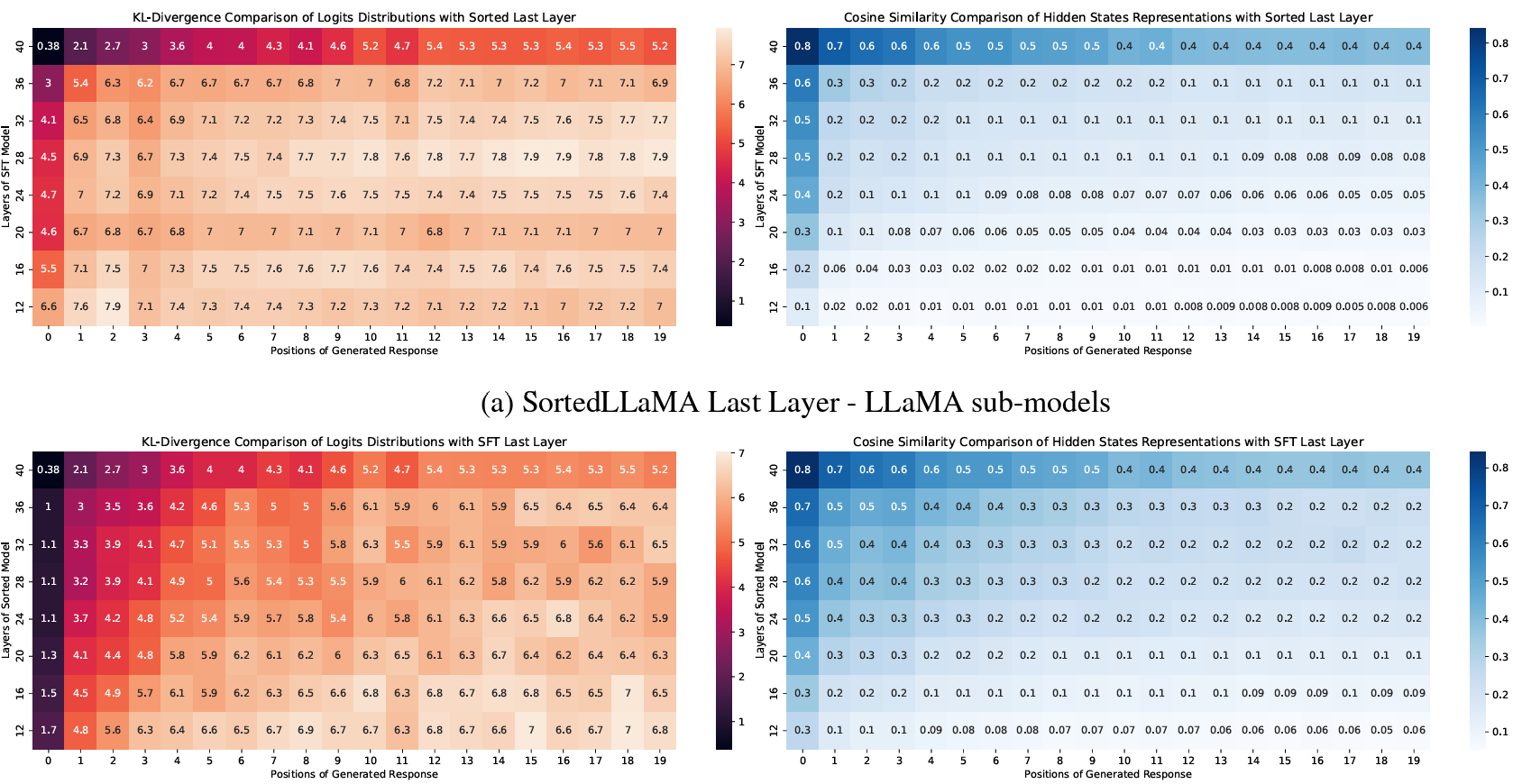 Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic InferenceIn Findings of the Association for Computational Linguistics: EACL 2024, Mar 2024
Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic InferenceIn Findings of the Association for Computational Linguistics: EACL 2024, Mar 2024


